
Technology Review of Dark
In case you haven’t heard of this shiny, new framework, Dark is a programming language, a structured editor, and infrastructure for building serverless backends.
Annnd my personal review is that it’s super dope 😍
I am very into static web generation (shout out to Jekyll + Github Pages) specifically because I can publish sites serverless-ly and for free.
And Dark is very much the backend equivalent in all of the best ways.
First Impressions 😍
Okay so I get my invitation, and it’s my first time in a beta program so I’m feeling very hush-hush, very hacker-in-a-dark-garage, very deep web.
Anywho, in reality you get an email, you ping an api to see if your username is available, you reply to the email with the username you want, and they reply with a login link.
I loved creating an account this way because it added to the rawness of the technology. It made me feel like I was one of the first 10 people using it, which is a great vibe when you’re hacking around in a new technology.
Also, after a few days, co-founder Ellen Chisa checked in to see how I was doing, which is a very cool opportunity to explain my experience.
Dark Documentation 😍
The first thing I do when I pick up a new technology is see how the documentation looks. Is it navigable? Is it clear? Are there examples of actual code I can copy and paste?
I used the how to guide to spin up an endpoint and MY STARS was it easy.
As I developed more, I consulted their language documentation, and back in February it was super helpful. All I lacked was a code snippet in each section. As of the date of this post, they’ve included a ton of code snippets and it is everything I ever needed!
Trace Driven Development 😍
Okay, so Trace Driven Development was totally new to me.
Trace Driven Development is capturing trace data before development, and then using it as a contract for the design of your component or system.
For example, if you’re creating an API endpoint…
- You create an empty endpoint to hit
- You throw your request at the endpoint
- The request is stored (traced)
- You use the information from the trace to build out the meat of your endpoint
I 100% recommend this, not only for your Dark development, but for any development of any backend. It was so handy in hooking up my Slackbot endpoints (more about this in a future post).
It was so handy because dark
- stores a pretty deep history of traces
- doesn’t make you guess what your integration contract might be
- keeps the trace UX really trim, so your debugging tools aren’t in the way
Darklang 😃
So there’s a language, Darklang, part of the Dark framework. I struggled for a few hours with the syntax, which is based off of statically typed functional languages, because I haven’t written in FPs in years.
BUT THEN I found that language documentation I was talking about earlier, and it was smooth sailing.
Co-founder, Paul Biggar, wrote a great post if you’d like to deep-dive into their choices for the language.
What parts of Dark did you use?
I’m including my code as an example, and that means it might be useful for you to know how they all hook together.
For more context, here’s my post on the project I used to evaluate this tech.
sequenceDiagram
participant D as Dark
participant S as Slack
participant V as Vue.js Web App
S->>D: This person signed up to be surveyed!
activate D
D-->>S: Cool, thanks!
D->>D: Store authentication tokens for later
D->>D: Generate random dates and times to survey people
loop Every minute
D->>D: Check if there are any surveys to send
opt If a survey needs to go out
D->>S: Send slack message with link to survey
deactivate D
S->>V: User clicks link to start survey
activate V
V->>D: User submits survey
deactivate V
D->>D: Store answers
end
end
V->>D: User clicks link to view survey results
D-->>V: Here's the data you need!
HTTP 😍
For the sake of simplicity, let’s ignore the Slackbot authentication endpoints.
That leaves two - what ended up being - pretty simple endpoints:
- POST a new survey
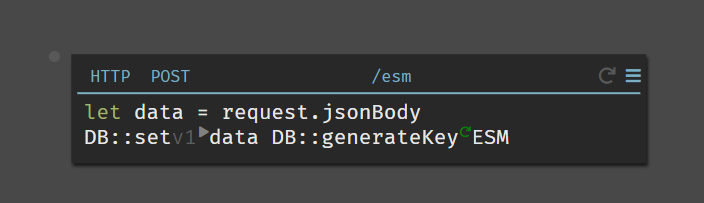
- GET all of this user’s surveys
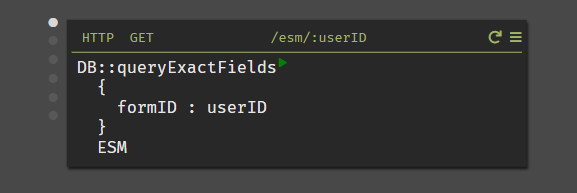
Creating an endpoint was the first thing I did with Dark. The beauty of it is that it’s live as soon as you create it. So I was able to start hitting the endpoint immediately, which - if you’re at all familiar with normal API development… that is never how it goes.
Notice how easy it is to
- Work with the request body in JSON
- Access a query parameter
Datastores 😍
Ohh databases *wistful sigh*…
Setting up these datastores was SO EASY. Thank you Dark for not having us make SQL queries. 👏👏
Here’s one of my tables
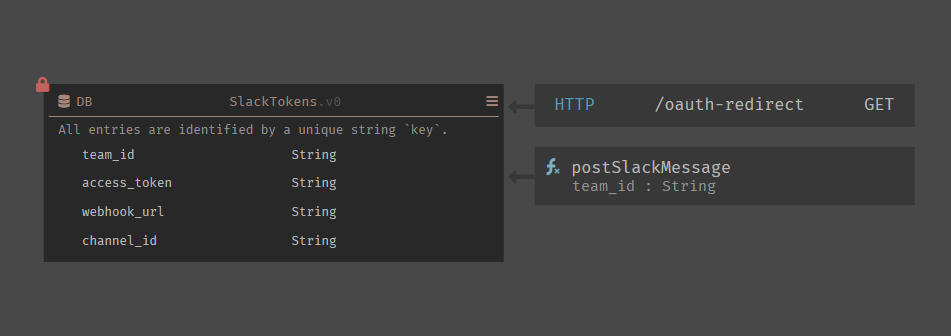
I love being able to see which of my other objects use the datastore. It made keeping track of my dependencies that much easier.
Cron 😍
Okay, let’s be honest, I’ve never really understood cron jobs. I’ve had a lot of friends and co-workers talk about them and it’s one of those just-smile-and-nod things for me.
BUT, I needed one for my backend in order to periodically check for surveys that need to be sent out.
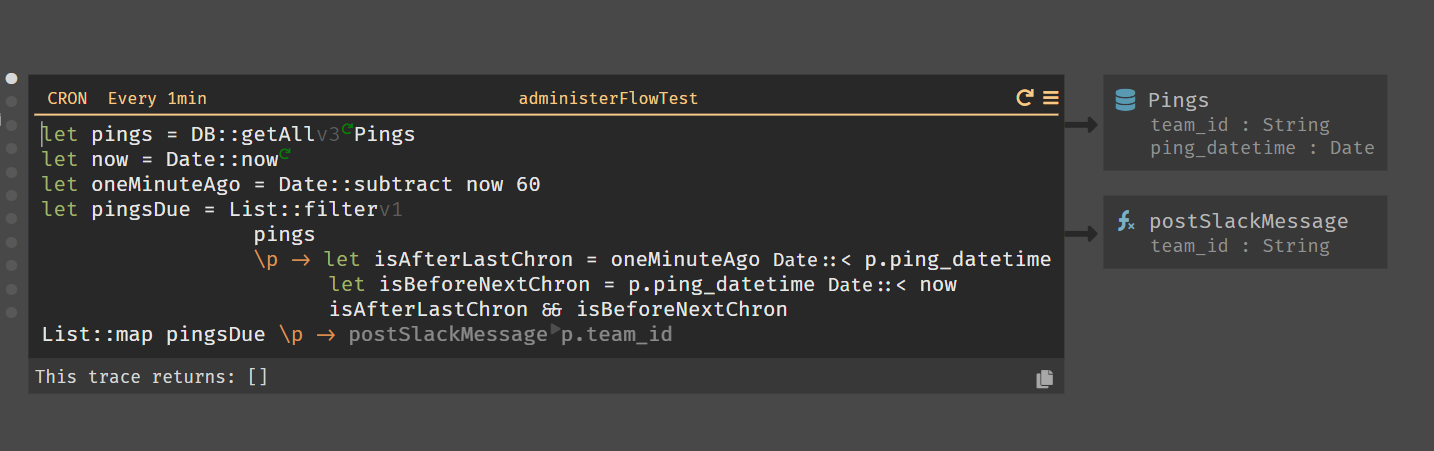
I’ve come to realize that once you take away the whole server part of a backend, cron jobs become way less intimidating.
Functions 😍
Okay functions are a great part of this tech. It let me extract out my crazzzyyy business logic which kept everything else nice and tidy.
I need to show you how crazy I had to get with a function…
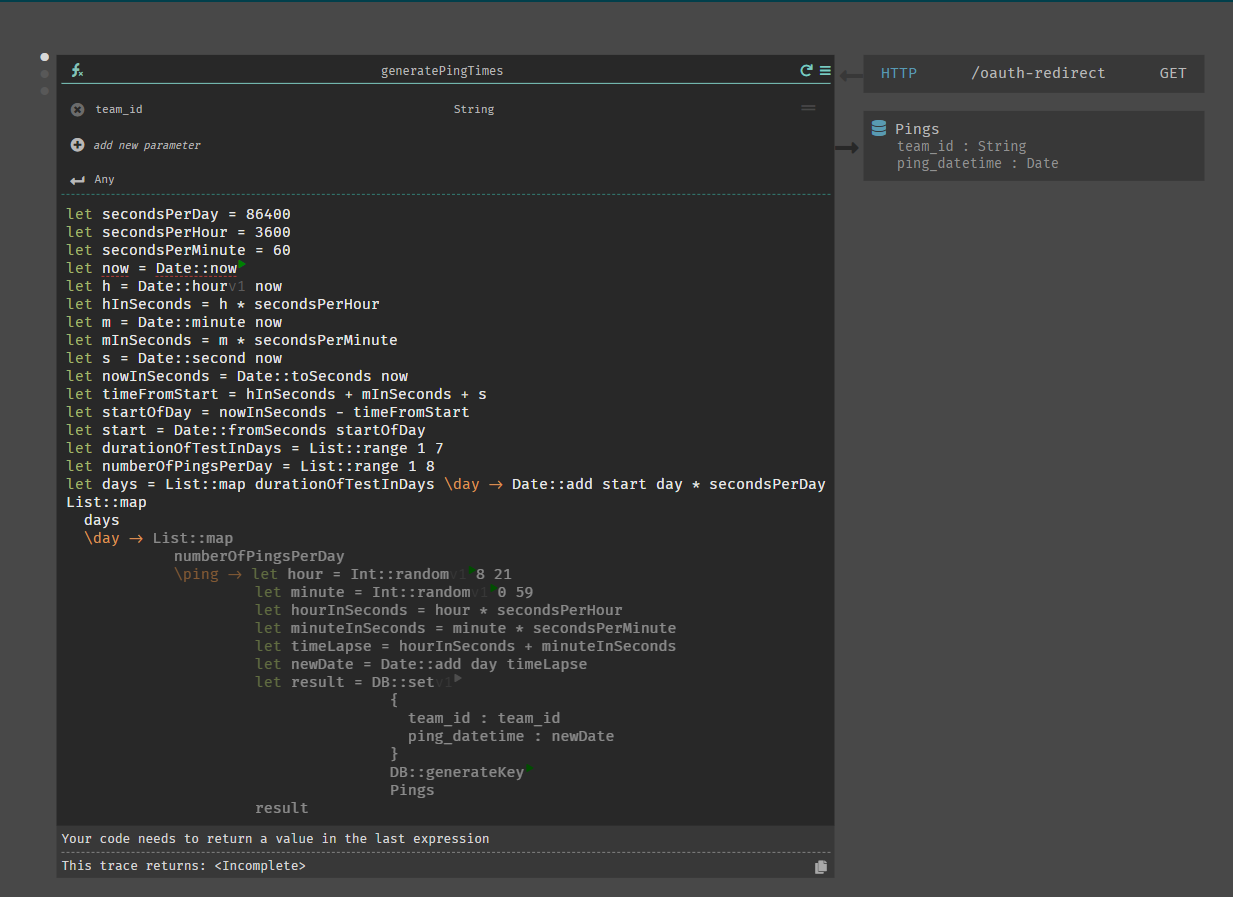
For the app, I needed to send 8 surveys a day for a week at random times during waking hours. So what you see is all the complexity behind randomly generating times without a randomness library 😂😭😬
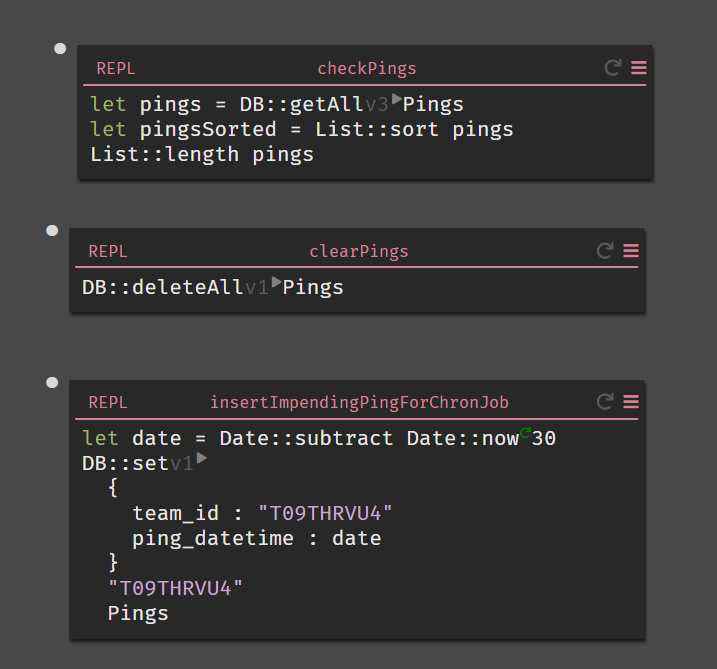
REPL 😍
I loved having the REPL component available while I was testing.
REPL made it super easy to
- Clear datastores out for editing
- Looking at everything I had in my datastores
- Testing my functions
Here are the ones I made
The best thing I learned from Dark…
(I’m sorry, I must say this again)
When you remove the server out of the equation, building a backend becomes way less intimidating, extremely quick to build, and results in a simpler collection of code.